大规模库存调度的算法实践
目录
大型的零售公司一般会自建(或租用)多个仓库来储存商品,以便满足不同区域的销售。理想情况是每个仓库的库存量都能匹配当地客户的需求。但在实际中,有些仓库可能会出现商品缺货或滞销的情况。
例如,某个商品在仓库A发生了缺货,但在仓库B却可能产生积压。这样一来,仓库A附近的客户要么无法下单,因此公司会损失销售利润;要么能够下单,但是商品会从比较远的仓库B发货,造成更高的物流费用和更长的运输时间。
公司为了增加销售利润,降低商品的配送成本和提升配送时效,于是希望在发生缺货或滞销之前,对多个仓库之间的库存进行调拨,期望满足客户需求。
库存调度问题
大型零售公司经营的零售品类丰富,例如有居家生活、服饰鞋包、美食酒水、个护清洁、数码家电等,商品类型多达上万种(甚至百万级别),商品体积和价值也有大有小。
库存调度就是让商品在不同仓库之间流转,目标是满足消费者的需求,同时改善消费体验和降低供应链成本(如下图所示)。
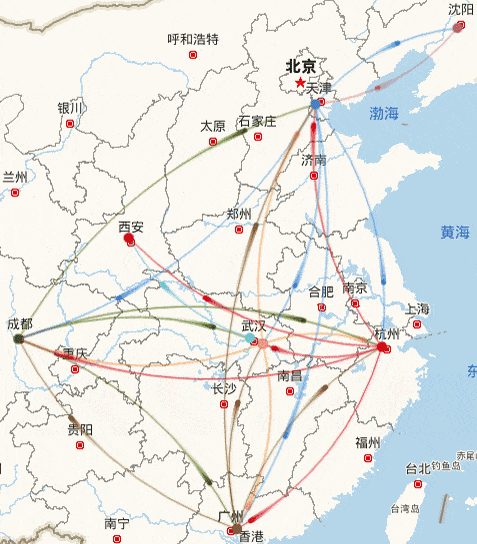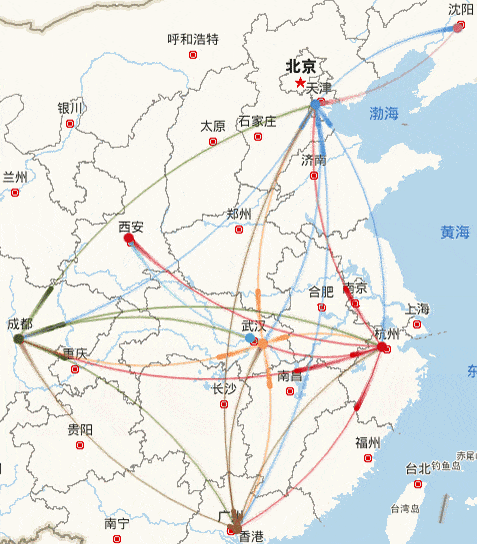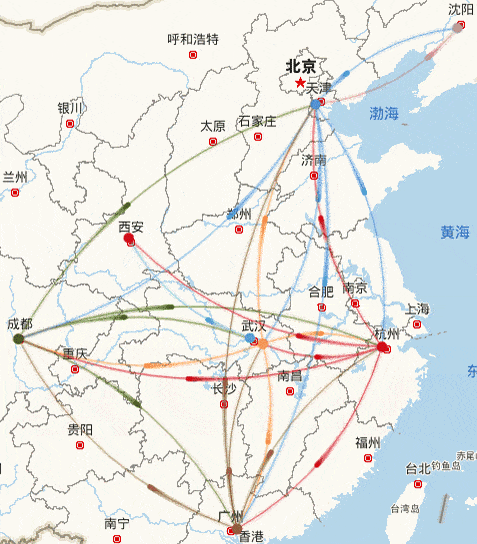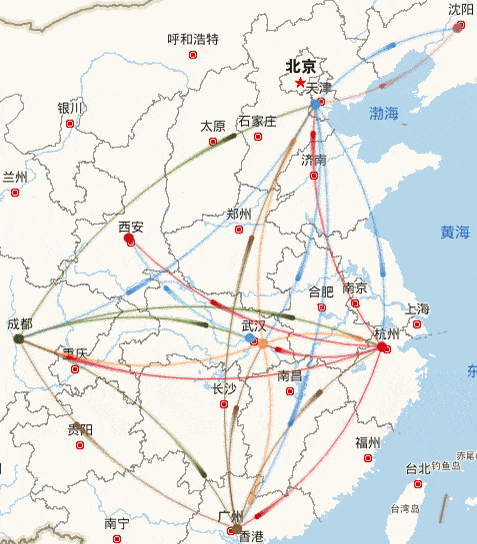
在这样的背景下,我们需要考虑如下问题:
需求预测 预测各仓库中商品在未来一段时间的需求,从而判断商品在仓库发生缺货或者滞销的风险。然后计算商品调拨量,即出库量或入库量。
如何调度 商品应该从哪调到哪,调拨量是多少?换句话说,需要计算商品的流向和流量。此外,应该安排多少运输车辆?
业务限制 在业务操作中,有非常多的限制。例如:
- 仓库产能有限,即每个仓库单天能出库的商品数量是有限的。
- 货车容量有限,而且容量有差异,例如12米5(67立方)和17米5(110立方)。
- 商品必须整箱调度,而且不同商品的箱规不同。
- 商品有流向限制,例如一些大型商品不支持调拨,还有一些商品只能单向调拨,即从A仓调到B仓可以,反之则不行。
成本控制 由于销售一般有淡季和旺季(例如电商的平销和大促),因此业务上要考虑不同的调拨策略。例如平销时期采用比较保守的调度策略,降低调拨成本,允许一定的本地仓缺货;而促销时期则采用激进的调拨策略,力保用户需求。
目标导向 业务目标包括两个部分:一是降低配送成本和配送时效;二是降低拆单率,从而提升用户体验。因此,我们设计的调度算法应该尽可能达成这两个目标。
从实践的角度来看,不仅要考虑上述“计算问题”,还应该从工程和产品的角度考虑,例如数据质量保障、系统的可用性、算法模块的可插拔和可配置、约束条件可扩展、产品交互等。
系统架构
整个系统的设计思路如下,分为数据、模型、接口和用户四层。
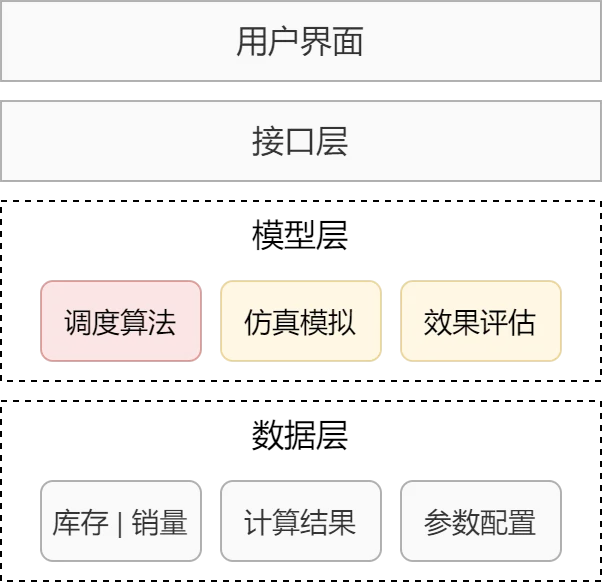
其中模型层中的调度算法整个系统的核心,也是接下来需要设计的关键部分;接口层把所有能力进行封装,然后与前端界面交互。
调度算法
在实际中,业务目标不仅多样化(时而侧重成本,时而偏用户体验),业务状况还可能发生变化,例如新增仓库、商品种类等等。这样一来,我们需要保障算法能力具有一定的可扩展性,即当业务发生变化的时候不用修改全部的算法。
我们把它分解成四个基本模块(如下图所示),从左到右依次执行。

下面我们详细介绍这四个模块的功能。
需求预测 仓库中商品的“多余量”和“不足量”是它对该商品的需求。多余量意味着商品需要从仓库调出,而不足量意味着需要从其它仓库调入该商品。需求预测模块的作用就是计算各仓库商品当前的需求。
- 输入:各仓库中商品的历史销量、商品在仓库的当前库存和在途库存。
- 输出: 各仓库中商品的多余量和不足量。
仓库的需求除了参考历史销量,还应该考虑业务目标。比如商品的“重要性”越高,仓库要准备的安全库存一般也会越大。
需求平衡 考虑四个仓库A、B、C、D和单个商品,其中仓库A的多余量是200,仓库B、C、D的不足量分别是100、200、300。此时 总多余量 与 总不足量 是不相等的,因此需求是不平衡的。
需求平衡模块的作用是调整多余量和不足量,使得总多余量等于总不足量。
- 输入:商品在各仓的需求(不足量和多余量)。
- 输出:商品在各仓的需求,满足平衡性要求。
这个问题看起来简单,但实际上还要考虑业务目标,例如降低拆单率。由于商品的日均需求(消耗速度)、重要程度(成本、利润)不同,我们发现如果简单地按比例分配,会造成一些问题,例如长尾商品得不到调拨,从而影响拆单率。
可以把上述需求平衡问题看成一个资源分配问题,然后考虑“合作博弈论”中的“公平”分配方案(参考TODO《团队合作如何分配利益?》,《如果银行破产,我能拿回多少钱?》)。
流向计算 计算商品的流向,即从哪个仓调出,调入哪个仓,以及对应的调拨数量。
- 输入:商品在各仓的需求(满足平衡性)。
- 输出:商品流向,即调出仓、调入仓和调拨量。
用一个简化的例子来说明流向计算问题(如下图所示):图中的节点代表仓库,节点的权重代表多余量(蓝色)和不足量(红色),边权代表了商品的单位运费。
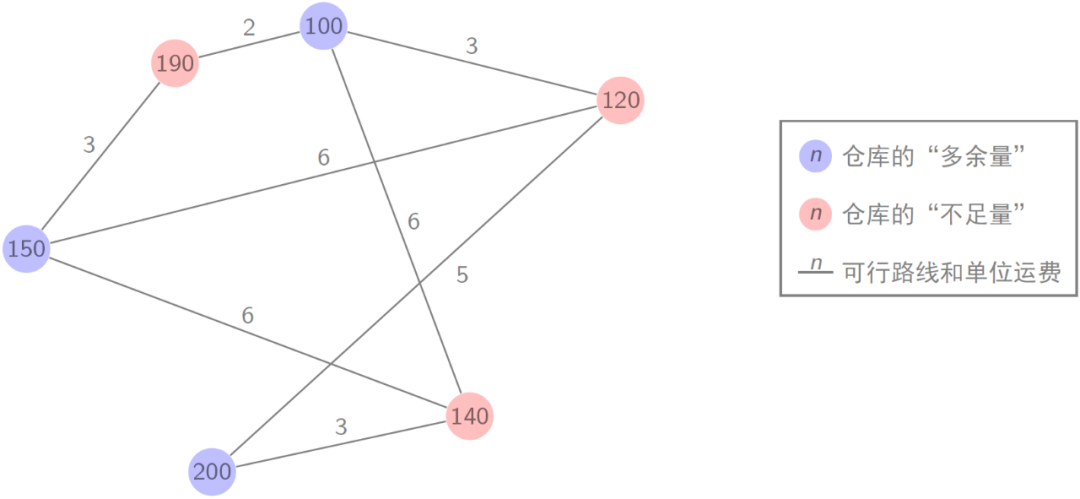
流向计算的目标是最小化商品的运输成本(一个线性规划问题)。
需要注意的是模型的输入还包含与业务目标和约束相关的数据(例如单位运费)。此外,实际业务中会有更多的限制条件,例如流向的限制、箱规和仓库产能,应该根据业务的实际情况来建模。
车辆安排 根据商品流向安排合适的货车,此时要考虑货车的容量和运输成本、商品的装箱体积。目标是最小化运输成本。
- 输入: 所有商品流向。
- 输出: 各仓库的调度车辆安排,即货车类型和对应的商品数量。 一般情况下,商品的装箱体积远小于货车容量。因此货车调度的装箱问题可以简化成一维装箱问题求解。
效果评估 相比如何设计系统与算法模块,更重要的是评估业务效果,即评估这套算法系统是否为业务带来了增量价值。可以从如下四个角度考虑。
异常监测
监控底层数据(例如历史销量,库存)的异常值。如发现异常,应该自动处理异常或报警,避免计算结果出错,从而造成业务上的损失。定期生成监测报告,评估系统的可靠性。
调拨报告
从操作层面来看,最终的调拨需要由人来执行,因此算法输出的结果需要能被人读懂。为了解释算法的结果,需要输出算法模型计算的中间值,包含算法模型和参数相关的信息,从而辅助业务员判断风险。
模型评估
模型开发阶段需要评估每个算法模块的效果,用来指导模型的迭代。常用的方法有两种:一种是自动化地构造测试数据,评估模型的好坏;另一种方式就是利用历史数据模拟算法的效果。
收益分析
根据业务指标(例如成本和时效),事后评估带来的增益效果,比如成本、时效和拆单率的降低。还可以通过仿真,评估收益上限,从而指导技术投入。换句话说,通过评估发现是否值得进一步投入资源迭代算法模型。
总结
本系统在实际业务中已稳定运行三年多,目前仅需一名业务员,可支持日均十万(甚至百万级)商品的调拨,每年可节省数千万小时的履约时长和数百万的配送费用。
设计一个算法系统并成功解决复杂的业务问题是令人激动的。这个过程中我们也遇到了一些困难,除了一些技术问题,更多的是沟通、协作和资源等方面的问题。
在算法设计中,我们充分考虑到业务的复杂性,因此没有考虑全局的优化模型,而是把它拆成了不同的子问题,分别求解。这样做的好处是当业务发生变化时,只需要调整对应的算法模块(子问题也更容易建模和求解)。然后利用仿真和数据分析,指导我们迭代算法模型,从而逼近最优解。
最后值得一提的是,我们的目标是解决问题,而不是为了追求算法模型和工程架构的高大上。这里用到的算法技术都是非常基础的,例如线性规划、统计等。
站在用户的角度去解决问题才是出发点,至于解决到什么程度,还需要考虑技术的投入产出比。