聊一聊电商中的需求预测
目录
本文讲一讲电商业务中的需求预测。先介绍业务中的应用场景,然后描述预测问题,再分析问题的难点,最后给出技术方案。
业务场景
需求预测的主要目的是补货,而补货需要提前计划。换句话说,不会等到缺货了再补。问题是什么时候补,以及补多少货。补多了占用资金,还增加仓储成本,补少了又损失销售。
需求预测除了补货,其他场景也会用到。下面举几个例子。
包材采购 运货需要包材,比如纸箱、塑料袋、填充物。商品的需求量越大,包材的需求量也越大。
库存调度 如果有多个仓库,仓库之间要调拨库存,那么调度量与商品的需求量相关。
人力安排 仓库要安排人力,人力需求取决于单量需求,与商品需求正相关。
选品定价 电商搞促销,涉及选品和定价,这就需要预测商品在某个价格段的需求量。
接下来描述问题。
问题介绍
需求预测就是预测商品未来的需求量。
具体来说,可以按商品、时段、渠道等维度,对问题进行定义。商品可以是 SKU、SPU、类目等,时段可以是日、周、月、年等,渠道有自营渠道、三方渠道等等。
从时效性看,可以分为离线预测和实时预测。离线预测产出离线数据表。实时预测是线上服务,由用户提供输入,例如价格、渠道等信息,然后输出预测结果。
从结果来看,可以分为点预测、区间预测、概率分布预测。常见的是点预测,每个预测结果是一个数值。区间预测输出的是一个范围,或者说区间。而概率分布预测,预测的是概率分布,既可以输出点预测值,又能输出区间。
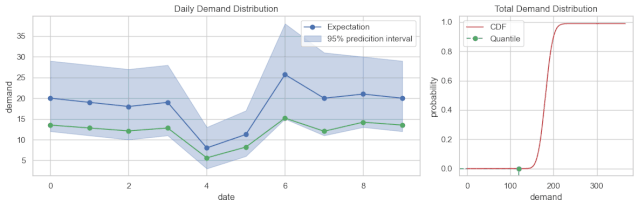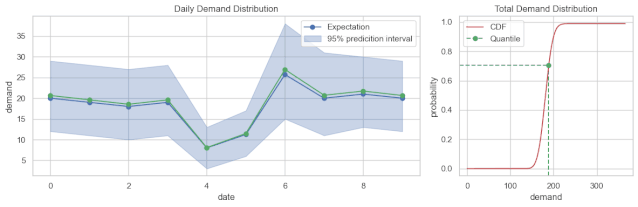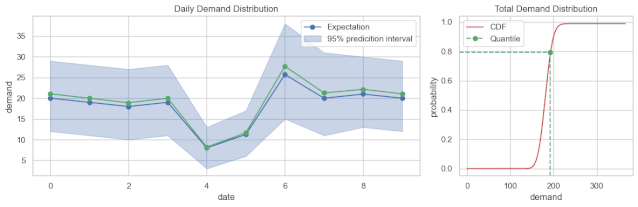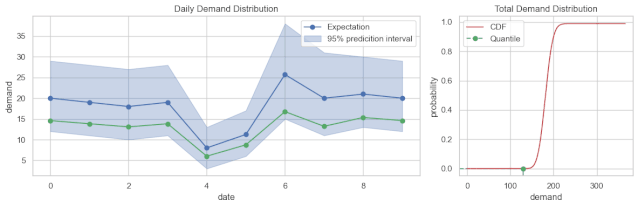
总结一下,需求预测不是一个问题,而是一系列的问题。定义它的时候,维度不同,取值不同,问题则不同,难易程度也不同。
难点分析
需求预测很难,技术只是一方面,更多是业务层面。处理好这些难点,是做需求预测的基础。
理解业务
这里说的业务,不是概念或者框架层面,而是在执行层面,是要理解数据背后的细节。比如说,缺货怎么定义。销量为零是不是?不一定,没有销量,但可以有库存。库存为零呢?也不一定,可能是清仓。如果是组合装,没库存也不影响单品销售。
这还没完,如果用户退货,导致库存为正,算不算缺货?计算库存的时候,还要看其他渠道,因为有些渠道可以共享库存,有些则不会。你看看,理解业务不简单。
业务变化
业务是快速变化的。这直接影响到商品的销售。下面举几个例子。
第一,商品迭代。包括上新、改进和废弃。产品在变,需求也跟着变。
第二,客户端迭代。电商业务的交易主要在线上,客户端的迭代,会影响流量入口,甚至是交易链路。
第三,运营策略变化。比如定价策略、运营栏目、促销玩法、图片文案等等,这些直接影响销售结果。
我们要思考,怎么捕捉这些变化。
周期性
电商业务有周期性,周期越长越难处理。下面说两个例子。
一是商品的季节性。比如衣服,大多只卖一季,次年出新款;二是促销活动,年年有大促,但玩法不同,定价也不同。
周期长或者重复性低,意味着历史数据的参考性就弱,于是预测就不好做。在估不准的情况下,我们要想办法降低损失。
脏数据
脏数据主要体现在数据的失效、异常、错误和缺失。由于业务变化、系统问题、操作不当、或者取数逻辑不一致等原因,脏数据很难避免。
如何改善数据质量,这个值得思考。
提前期
商品从下订单,到生产,再到入库,总的时间称为提前期,这是补货需要提前的时间长度。
不同商品的提前期不同,短的两周左右,长的六个月甚至一年。提前期越长,未知因素越多,越不容易做预测。
我们想一想,如何缩短提前期,比如减少审批。
解释性
从算法的角度看,预测效果最重要。但这样不够,还要能解释预测逻辑,并且在出现异常后,给出原因分析。这么做是必要的:一是容易发现异常;二是方便调整预测结果;三是让使用方放心。
难点是怎么解释,才能让人信服。
技术方案
从技术角度来看,需求预测的流程大致如下。
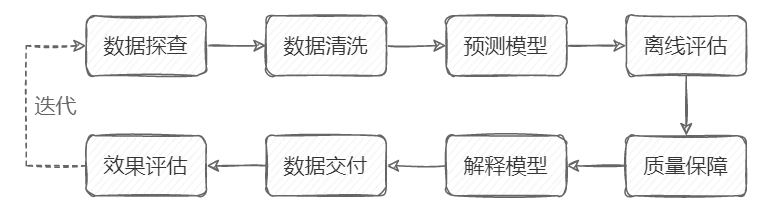
开发:数据探查、数据清洗、预测模型、模型评估
上线:质量保障、解释模型、数据交付、效果评估
这里强调一下数据探查,这个很重要,不能走过场。前期的分析和可视化,可以发现规律,甚至是业务问题,然后快速验证想法。这样可以减少试错的成本。
图上各环节不多解释,下面重点讲模型和评估。
模型
常见的预测模型有四类:
规则模型
根据人的经验来拟合历史数据。例如,先计算基础销量,再叠加节日、营销、季节等参数。不同参数可以用不同的数据去拟合。常用的技术是统计和回归。
它的优势是解释性好,缺点是工作量大。业务如果变化快,规则就容易失效,就需要更新规则。
时序模型
主要指低维的时间序列模型,比如自回归模型(ARIMA)、指数平滑方法(Holt-Winters)、分解方法(STL),或者这些方法的结合(Prophet)。
时序模型的优点是可以拟合周期性和趋势(下图),缺点是不适合处理大量特征。
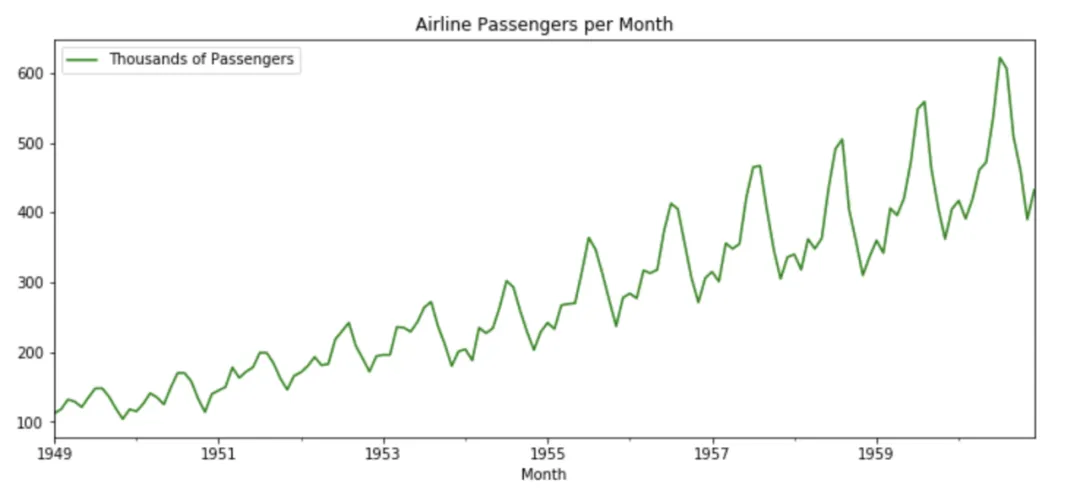
话务量、单量、流量等数据,常常会有这种特点。
决策树模型
决策树是树结构的分类模型。输入特征向量,经过树的节点判断,然后输出预测值。常见的树模型有 XGBoost、LightBGM 等。
树模型的优点是,能够处理较多的特征,可以把售价、商品属性、节假日、运营玩法、优惠券、红包等多种因素,都综合考虑进来,而且对计算资源要求不高。
树模型的缺点主要有两个:一是需要做特征工程,清洗数据和构建特征有一定的成本;二是由于考虑因素较多,训练和推断是黑盒,不容易解释结果。
深度学习
通过深度神经网络,可以自动化地对特征进行加工(比如做卷积),进而去拟合海量的数据,比如 DeepAR、WaveNet、Transformer 等。
深度学习的好处是工程化方便,缺点是不好解释,而且对计算资源要求高。
做个小结,做需求预测时,模型固然重要,但它不是全部,也不必追求高级感。要根据业务实际,选择合适的模型,多关注它的业务价值。
评估
要评估预测效果,就要看准确率,或者说偏差率。但定义它并不容易。
举个例子,业界常用”百分比绝对误差“,即预测偏差的绝对值与真实值的比值。注意到,如果预测值偏低,误差的上界是100%;如果预测偏高,误差上界是无穷。换句话说,这个误差指标对偏高的惩罚大,于是算法会倾向于输出偏低的结果,于是容易造成缺货。
定义预测的误差指标时,要考虑下游的业务目标,比如说是补货,还是营销,或者安排人力等等。不同的业务,对偏差的要求不同。例如,人力安排可以接受预测偏高,但不太接受偏低。由于篇幅有限,关于误差指标的讨论这里不展开。
总结
需求预测很难,因为需求有随机性。除此以外,既有业务因素,也有技术因素。要做预测,算法模型很重要,但模型不是全部。其他环节也很重要,比如信息同步、审批流程、物流运输等等,这些都可以去优化预测或者补货的效果。
既然预测是不准的,如何衡量这种不确定性,又如何降低损失,也是要考虑的问题。思路是这样,用概率分布描述不确定性,然后用计算每一种情况下的损失,选择平均损失最小的方案。这就是决策模型做的事。
从补货场景来看,需求预测与补货决策,应该看成一个系统,这样才能让决策效率和质量更高。对补货系统感兴趣的朋友可以参考这篇《智能补货系统的设计思路》。