时间序列模型简介
- 邱显
- March 20, 2020
目录
平稳序列
时间序列是一列观测值 $X_t$ 的集合,其中每个观测值是在时段 $t$ 观测所得 ($t$ 是自然数)。给定时间序列 $\set{X_t}_{t=1}^n$,如果对任意的 $t=1,\ldots,n$,它满足下列条件:
- $\text{var}(X_t)<\infty$
- $\mathbb{E}(X_t) = \mu$
- $\text{cov}(X_r, X_s) = \text{cov}(X_{r+t}, X_{s+t}), \forall r,s = 1, …, n$
我们把它叫做(弱)平稳 (weakly stationary) 序列。下文我们简称平稳序列。
通俗地讲,平稳序列的期望, 方差, 协方差不随时间变化。例如,$X_t$ 服从同一个分布时,它是平稳的。
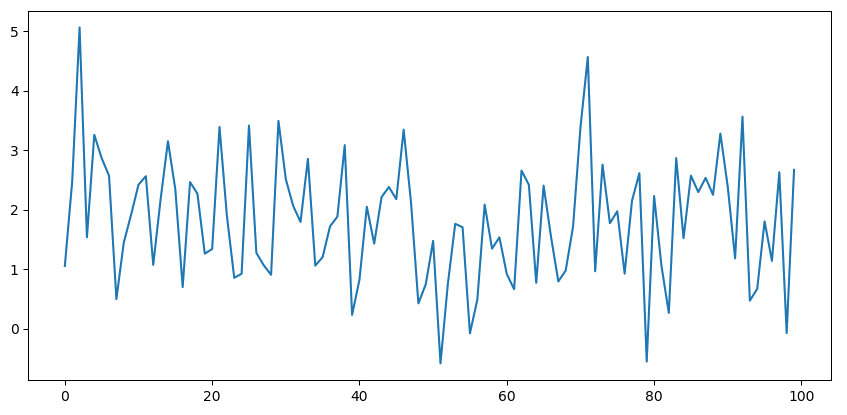
例1 下图中的时间序列由 $X_t\sim N(2, 1)$ 生成。从直观上看,这个序列是"平稳的"。
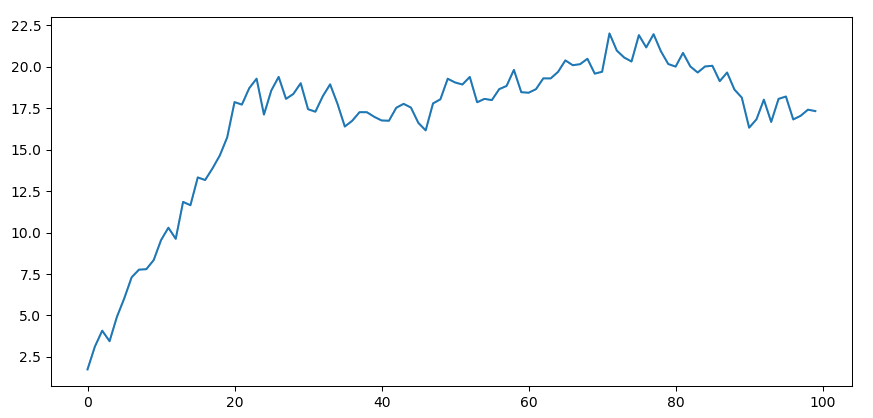
例2 下图的中的时间序列由 $X_t= 2 + 0.9X_{t-1}+W_t$ 生成,其中 $X_0=0$,$W_t= N(0, 1)$。它起初有明显地增长,然后趋于平稳。利用 ADF 检验(详情见下文),我们发现该序列是平稳的 (p-value < 0.01)。
说明 弱平稳性的"弱"主要体现在时间序列在全局上是平稳的,即,时间序列局部是波动的,但整体上看是平稳的,或者随着时间的变化其样本的均值收敛。
判断样本的平稳性
可以用统计学中假设检验的方法来判断样本的平稳性。常用的是 Augmented Dickey-Fuller (ADF) 检验1。
- Null Hypothesis $(H_0)$:样本中存在 unit root2。如果接受 $H_0$,则意味着样本是非平稳的。
- Alternate Hypothesis $(H_1)$:样本中不存在 unit root。如果拒绝 $H_0$,则意味着样本是平稳的。
在显著水平 $\alpha=0.05$ 的条件下,我们可以通过计算 p-value 来接受或者拒绝$H_0$:
- $\text{p-value} > 0.05$: 接受$H_0$。
- $\text{p-value} \leq 0.05$: 拒绝 $H_0$。
Python3 中 statsmodels.tas.stattools 中的 adfuller 函数3 实现了 ADF 检验。使用方法如下所示。
from statsmodels.tsa.stattools import adfuller
def test_stationarity(data, alpha=0.05, print_detail=True):
""" Test stationarity of time series data.
:param data: time series data, formatted as list
:param alpha: significance level.
:param print_detail: if True print additional information.
"""
result = adfuller(data)
is_stationary = True if result[1] <= alpha else False
if print_detail:
print('ADF statistic: %f' % result[0])
print('p-value: %f' % result[1])
print('critical values:')
for key, value in result[4].items():
print('\t%s: %.3f' % (key, value))
return is_stationary
时间序列模型
前面之所以介绍平稳序列的概念及检验方法,是因为它是很多基础的时间序列模型的前提假设。在本节我们介绍一些常见的时间序列模型(更多内容可以参考4, 5)。
AR(p)
AR 代表自回归 (Autoregression)。假设时间序列 $\set{X_t}$ 是平稳的, 它可以被表示成如下形式: $$X_t = \delta + \sum_{i=1}^p \phi_iX_{t-i} + W_t.$$
- $\delta$ 是常数。
- $W_t\overset{\text{iid}}{\sim} N(0, \sigma^2)$,它表示时段$t$的误差(随机变量)。
- $p$ 代表自回归阶数。
MA(q)
MA 代表移动平均 (Moving Average)。假设时间序列 $\set{X_t}$ 是平稳的,它可以被表示成如下形式: $$X_t = \delta + \sum_{i=1}^q \theta_iW_{t-i} + W_t.$$
- $\delta$是常数。
- $W_t\overset{\text{iid}}{\sim} N(0, \sigma^2)$,它表示时段 $t$ 的误差(随机变量)。
- $q$ 代表移动平均阶数。
ARMA(p,q)
ARMA 模型是 AR 和 MA 的组合。假设同上。它可以被表示为如下形式: $$X_t = \delta + \sum_{i=1}^p \phi_iX_{t-i} + \sum_{i=1}^q \theta_iW_{t-i} + W_t.$$
- $p$ 是自回归阶数
- $q$ 是移动平均阶数
ARIMA(p,d,q)
ARIMA 模型是 ARMA 模型的推广,全称是 Autoregressive Integrated Moving Average。当时间序列 $\set{X_t}$ 不满足平稳性时,我们通常使用 差分 的技巧把序列变得平稳,然后再应用ARMA模型。
参数 $d$ 代表差分的阶数。下面是差分的计算公式 ($\Delta$ 为差分算子):
- 一阶差分 $\Delta X_t = X_t - X_{t-1}$
- 二阶差分 $\Delta^{(2)} X_t = \Delta(X_t-X_{t-1}) = X_t - 2X_{t-1}+X_{t-2} = (1-\Delta)^2X_t$
- $d$ 阶差分 $\Delta^{(d)} X_t = (1-\Delta)^dX_t$
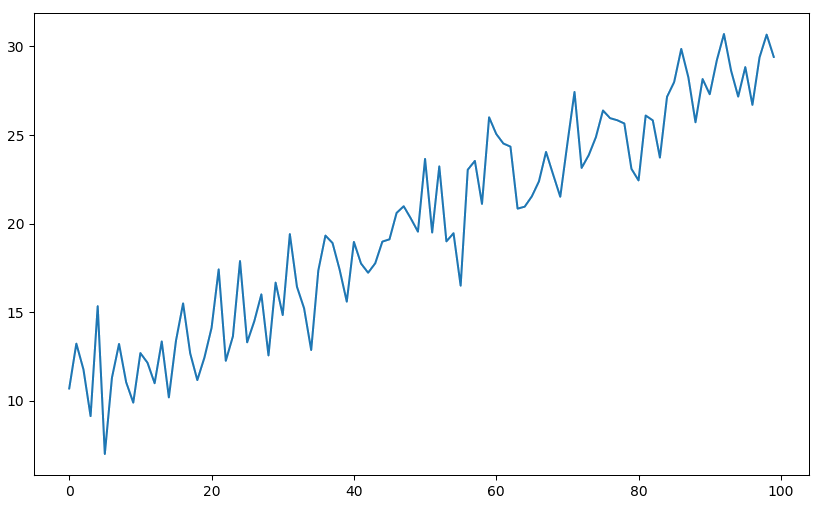
例3 下图是原始的时间序列。通过观察,它的均值有明显的上升趋势且不收敛,因此不是平稳序列 (ADF检验的 p-value 为0.94)。
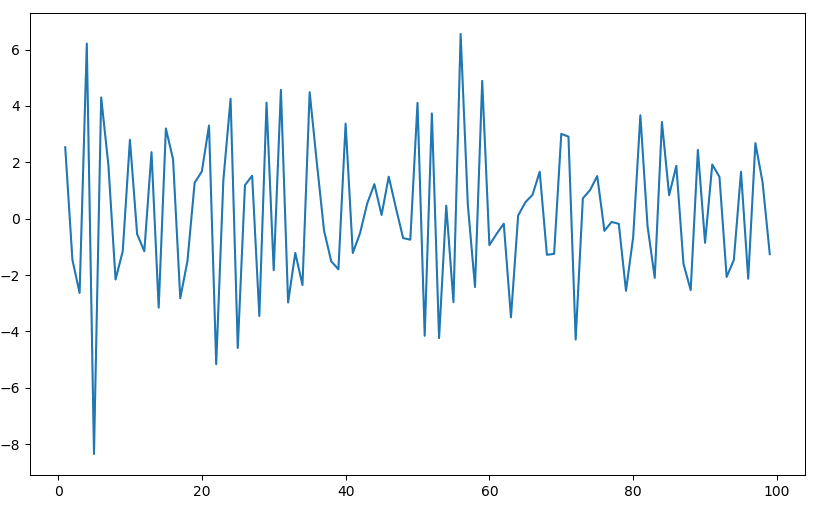
对该序列进行一阶差分后, 我们得到如下平稳的时间序列 (p-value为0.00)。
ARIMA(p,d,q) × (P,D,Q,s)
该记号代表季节性(或周期性) ARIMA 模型,详细的表达式可以参考4(4.1 Seasonal ARIMA models),其中
- $p,d,q$ 的意义同上。
- $P$ 代表周期性自回归阶数 (前 $P$ 个周期对应观测值的自回归)。
- $D$ 代表周期性差分阶数。
- $Q$ 代表周期性移动平均阶数 (前 $Q$ 个周期对应的移动平均)。
- $s$ 代表一个周期的长度。
我们可以把它看成两阶段模型:第一阶段在全局使用 ARIMA(p,d,q);第二阶段通过指定周期长度 $s$,再利用 ARIMA(P,Q,D) 模型考虑周期之间的关系。
例4 考虑如下周期性的平稳时间序列 ($s=18$)。
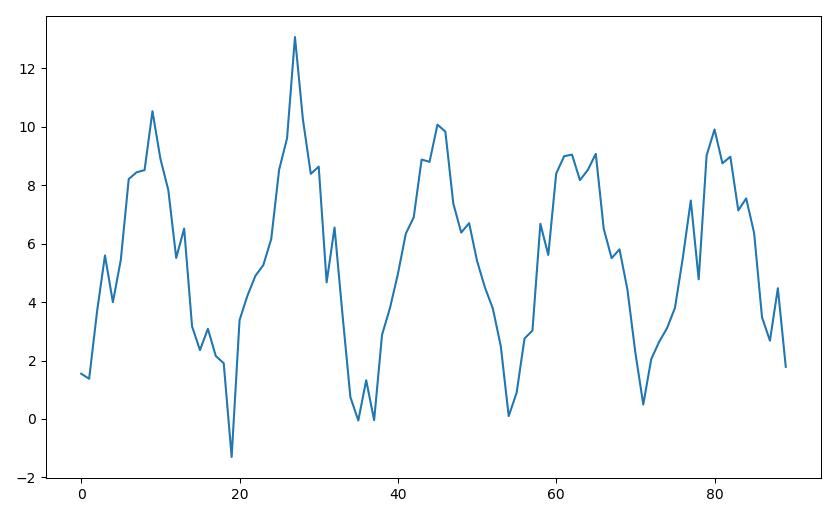
对序列进行周期性差分: $Y_t = X_t - X_{t-18}$ 得到新的时间序列 $\set{Y_t}$ 如下图所示(红色部分)。
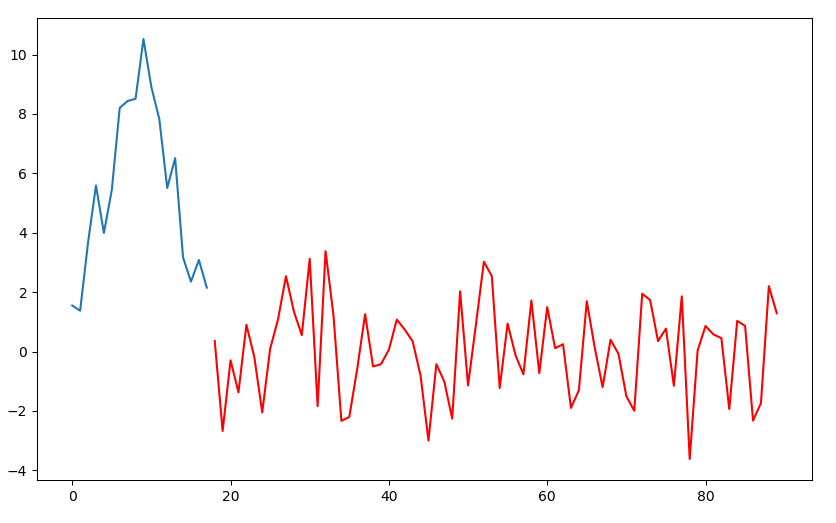
通过使用周期性差分,我们可以把原有时间序列的周期性移除。同理,通过采用周期性的自回归和移动平均系数,我们可以把周期之间的依赖关系考虑进模型。
例5 考虑周期 s=18 的数据(蓝色曲线)。用 $\text{ARIMA}(1,0, 0)$ 和 $\text{ARIMA}(1, 0, 0)\times(0, 1, 0, 18)$ 分别进行预测的结果如下。
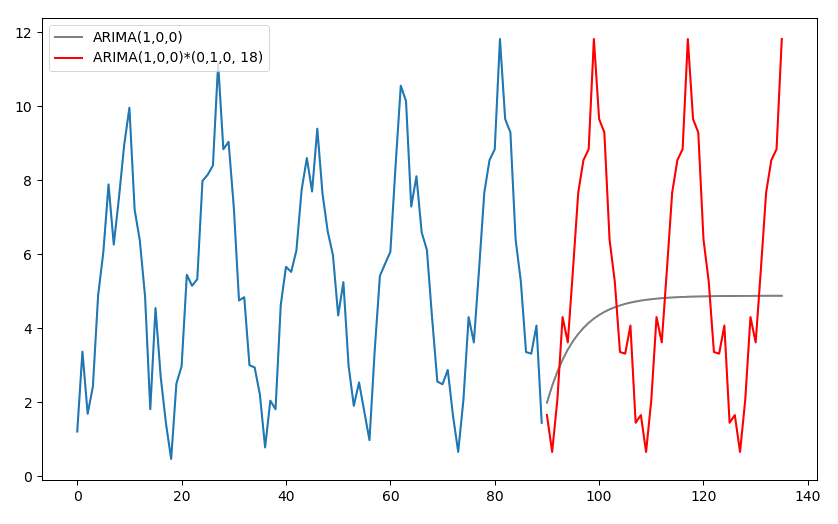
不考虑周期性的 ARIMA 模型的预测结果(灰色曲线)逐渐收敛到时间序列的均值。由于序列是平稳的,这样的预测结果符合我们的期望。考虑到该时间序列有比较强的周期性,且通过观察发现周期 $s=18$。在本例中,我们仅使用周期差分,,最终得到了如图所示(红色曲线)的周期性预测结果。
ARCH(p)
ARCH 的全称是 Autoregressive Conditionally Heteroscedasticity,它可以用来考虑样本的方差随着时间变化(或震荡)的时间序列。设时间序列${X_t}$ 是平稳的,$\text{ARCH}(p)$ 模型可以被表示成如下形式:
$$X_t = \sigma_tW_t,\quad W_t \overset{\text{iid}}{\sim} N(0,1) $$ 其中 $$\sigma_t^2 = \alpha_0 + \sum_{i=1}^p \alpha_iX_{t-i}^2.$$
- $p$ 代表 $X_t^2$ 的自回归阶数。
GARCH(p,q)
GARCH 即 Generalized ARCH, 是ARCH模型的推广6. 设时间序列${X_t}$是平稳的, $\text{GARCH}(p,q)$模型可以被表示成如下形式: $$X_t = \sigma_tW_t,\quad W_t \overset{\text{iid}}{\sim} N(0,1) $$ 其中 $$\sigma_t^2 = \alpha_0 + \sum_{i=1}^p \alpha_iX_{t-i}^2 + \sum_{i=1}^q \beta_i\sigma^2_{t-i}.$$
- $p$代表$X_t^2$的自回归阶数.
- $q$代表$\sigma_t^2$的移动平均阶数.
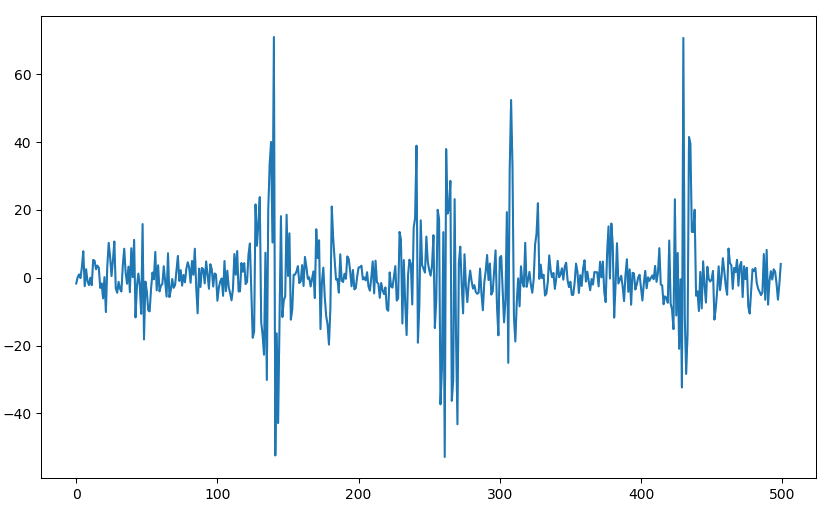
说明 ARCH/GARCH 随机过程产生的数据是什么样的? 前面提到它们允许 样本的方差 随时间变化,但是由于$\set{X_t}$ 必须满足平稳性(前提假设),因此样本的方差从局部看是变化(震荡)的,但从整体看应该是"平稳的"序列。例如下图是一个$\text{GARCH}(1,1)$ 过程生成的时间序列 ($\alpha_0=5, \alpha_1=\beta_1=0.5$)。
VAR(p)
VAR 即 Vector Autoregression,它是多变量的自回归模型。类似地,我们有 $\text{VARMA}(p, q)$,它是 $\text{ARMA}(p,q)$ 的向量版本。需要注意的是,VARMA 模型处理的时间序列可以有趋势。我们不做详细的展开,感兴趣的读者可以参考4章节11.2: Vector Autoregressive models VAR(p) models。
参数选择
给定时间序列的观测样本,选定预测模型之后如何确定模型的参数? 本节我们介绍两种常用的方法:1. 画出 ACF/PACF 图,然后观察出 $p,q$ 的值;2. 通过计算相关的统计指标,自动化地选择参数。
ACF
ACF的全称是 Autocorrelation Function。对变量 $h=1,2, …$,ACF的值代表 $X_t$ 与 $X_{t-h}$ 之间的相关性。 $$\text{ACF}(h) = \frac{\text{cov}(X_t, X_{t-h})}{\text{var}(X_t)}$$
PACF
PACF 的全称是 Partial Autocorrelation Function。对变量 $h=1,2,…$,PACF 的值代表已知 $X_{t-1}, … X_{t-h+1}$ 的条件下,$X_t$与$X_{t-h}$之间的相关性。
$$\text{PACF}(h) = \frac{\text{cov}(X_t,X_{t-h}|x_{t-1}, … x_{t-h+1})}{\sqrt{\text{var}(X_t|x_{t-1}, … x_{t-h+1})\text{var}(X_{t-h}|x_{t-1}, … x_{t-h+1})}}$$
例6 设$W_t\sim N(0, 1)$。考虑下面三个模型生成的时间序列,并计算相应的 ACF/PACF。
$\text{AR}(1): X_t=2 + 0.5X_{t-1}+W_t$
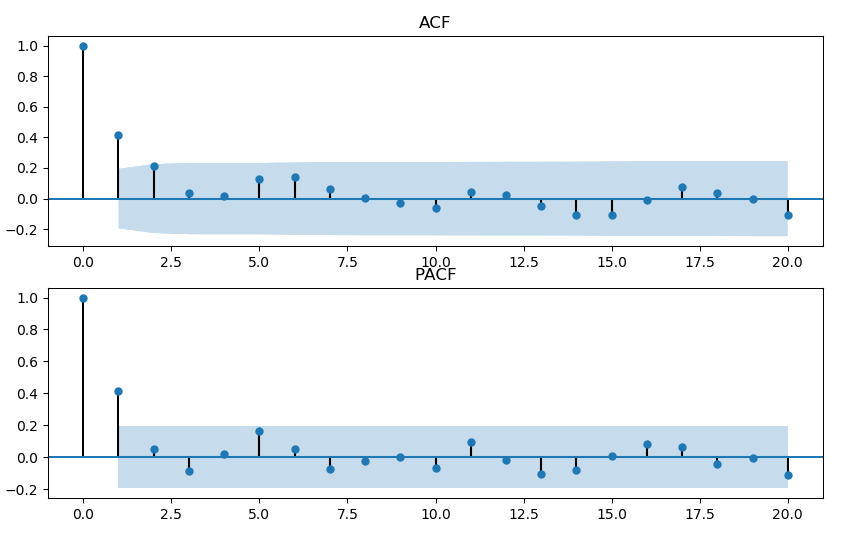
$\text{MA}(1): X_t=2 + 0.5W_{t-1}+W_t$
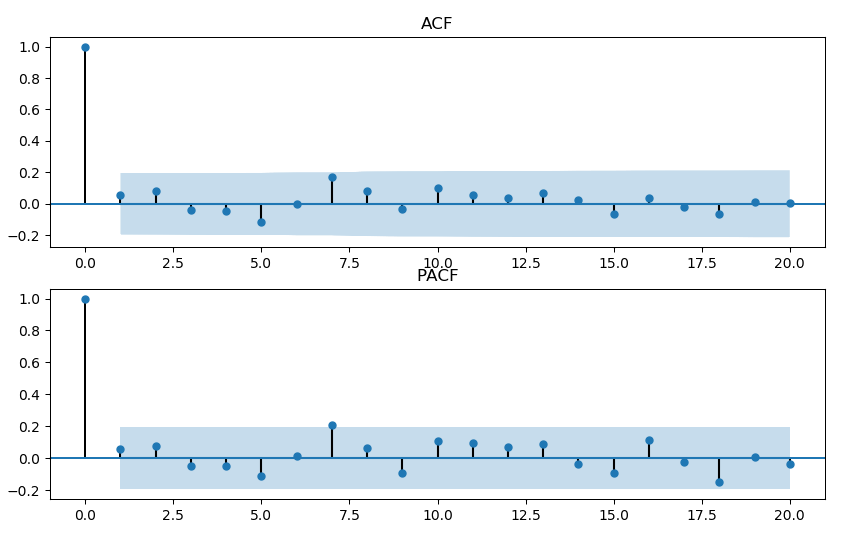
$\text{ARMA}(1,1): X_t=2 + 0.5X_{t-1}+ 0.5W_{t-1}+W_t$
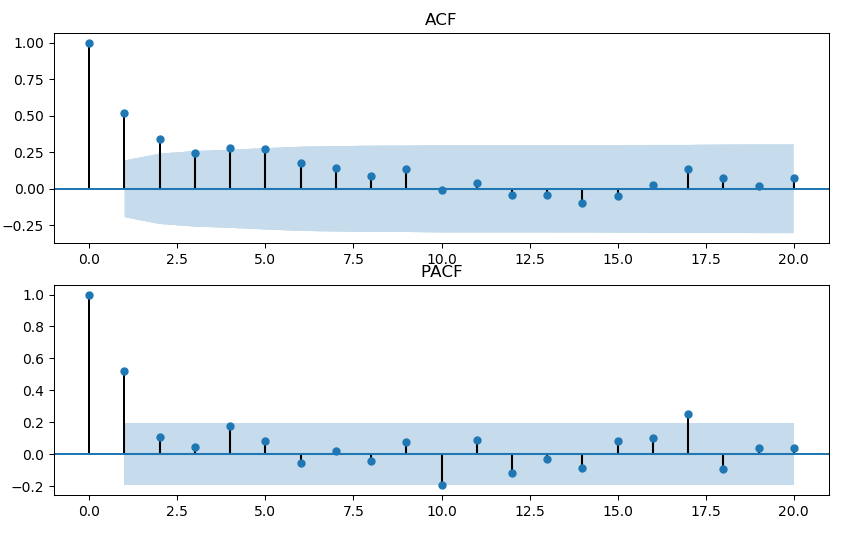
指导原则 4
| 模型 | ACF | PACF | 说明 |
|---|---|---|---|
| AR(p) | 逐渐趋近于0或像正弦曲线一样收敛到0 | 前$p$个值非常显著, 其余的值不显著 | $p$值主要参考PACF |
| MA(q) | 前$q$个值非常显著, 其余的值不显著 | 逐渐趋近于0或像正弦曲线一样收敛到0 | $q$值主要参考ACF |
| ARMA(p,q) | 逐渐趋近于0或像正弦曲线一样收敛到0 | 逐渐趋近于0或像正弦曲线一样收敛到0 | $p,q$值靠猜 |
自动化地决定参数
基本思想是通过计算一些指标,并选择参数使得相关的指标值尽可能小。下面介绍一些常用的指标。
为方便描述,我们先定义一些记号。
- $n$ = 样本的大小
- $k$ = 模型中需要拟合的参数数量(例如正态分布有的数量是2:$\mu$ 和 $\sigma$)
- $L_{\max}$ = 通过最大似然估计得到的最大 Likelihood
AIC(Akaike Information Criterion)7
$$\text{AIC} = 2k - 2\ln(L_{\max})$$
AICc8
它是 AIC 的改良版,为了解决小样本过拟合的问题。 $$\text{AICc} = \text{AIC} + \frac{2k^2 + 2k}{n-k-1}$$
BIC9
BIC 的全称是 Bayesian Information Criterion,也称为 Schwartz Criterion, SBC, SBIC。
$$\text{BIC} = \ln(n)k - 2\ln(L_{\max})$$
HQIC10
HQIC 的全称是 Hannan–Quinn Information Criterion。
$$\text{HQIC} = 2k\ln(\ln(n)) -2\ln(L_{\max})$$
建议在实际中综合考虑这些指标。
参考资料
Wikipedia. Augmented Dickey-Fuller test. ↩︎
Dickey, D. A.; Fuller, W. A. Distribution of the Estimators for Autoregressive Time Series with a Unit Root. Journal of the American Statistical Association. 74(366): 427–431, 1979. ↩︎
https://www.statsmodels.org/dev/generated/statsmodels.tsa.stattools.adfuller.html ↩︎
Lecture notes of Applied Time Series Analysis (SATA 510). The Pennsylvania State University. ↩︎ ↩︎ ↩︎ ↩︎
Jan Grandell. Time series analysis (lecture notes). ↩︎
Bollerslev, T. Generalized autoregressive conditional heteroscedasticity. Journal of Econometrics, 31, 307–327, 1986. ↩︎
Hirotugu Akaike. A new look at the statistical model identification, IEEE Transactions on Automatic Control, 19 (6): 716–723, 1974. ↩︎
Wikipedia. https://en.wikipedia.org/wiki/Akaike_information_criterion#AICc. ↩︎
Schwartz E.S. The Stochastic Behavior of Commodity Prices: Implications for Valuation and Hedging’. J Finance 52(3) Papers and Proceedings Fifty-Seventh Annual Meeting, American Finance Association, New Orleans, Louisiana, 923-973, 1997. ↩︎
Hannan, E. J. and B. G. Quinn. The Determination of the order of an autoregression, Journal of the Royal Statistical Society, Series B, 41: 190–195, 1979. ↩︎